
Durante años, muchos medios compitieron por aparecer en la primera página de Google. Ahora empieza otra competencia: lograr que sus contenidos sean encontrados, comprendidos, citados y reutilizados por sistemas basados en modelos de lenguaje. Ya no basta con publicar bien. También conviene estar estructurados para ser entendidos por máquinas inteligentes.
Por Néstor Altuve / info@nestoraltuve.com
Hay una pregunta que ya no debería estar confinada al equipo de tecnología, ni al área de SEO, ni a una conversación marginal sobre innovación: cuando un sistema de inteligencia artificial busca una respuesta sobre un tema de actualidad, ¿puede encontrar, interpretar y atribuir correctamente el contenido de su medio?
La pregunta parece técnica. En realidad, es profundamente estratégica.
Porque en el nuevo entorno digital, cada vez más personas no llegarán primero a una portada, a una home o incluso a una página de resultados tradicional. Llegarán a una respuesta generada, a un resumen conversacional, a una recomendación sintetizada o a una cita construida por un sistema de IA. Y en ese entorno, la calidad periodística sigue siendo decisiva, pero ya no alcanza por sí sola. La estructura empieza a importar casi tanto como el contenido.
Eso es, en términos simples, lo que significa “LLM discovery”: la capacidad de un contenido para ser descubierto, comprendido, relacionado con el contexto correcto y, en el mejor de los casos, citado o recomendado por sistemas basados en grandes modelos de lenguaje.
A medida que los sistemas de inteligencia artificial descubren, procesan, resumen y reutilizan contenidos periodísticos, emerge una tensión que ya no puede tratarse como un asunto periférico. Los medios necesitan ser encontrados, comprendidos y atribuidos en estos nuevos entornos. Pero al mismo tiempo crece la inquietud por el uso de su contenido sin suficiente reconocimiento, contexto o retorno económico. Es, sin duda, un tema álgido. Y seguirá siéndolo. Sin embargo, el error sería abordarlo solo desde la queja, el miedo o la lógica defensiva. La discusión de fondo no debería limitarse a si la IA usa o no usa contenido periodístico, sino a bajo qué condiciones lo hace: con qué nivel de atribución, con qué transparencia, con qué límites, con qué trazabilidad y bajo qué esquemas de compensación o intercambio de valor. Para los medios, aquí no solo está en juego la protección de su propiedad intelectual. También está en juego su capacidad de conservar contexto, marca, autoridad y monetización en una nueva capa de intermediación digital. Y para las empresas de IA, también debería estar claro que el acceso sostenible a contenido confiable, actualizado y bien producido no puede construirse sobre relaciones ambiguas o desequilibradas. Por eso, más que una guerra sin salida, lo que se necesita es avanzar hacia acuerdos beneficiosos para ambas partes. Acuerdos que reconozcan el valor económico, editorial y social del periodismo, y que al mismo tiempo permitan que los sistemas de IA accedan a información de calidad bajo reglas claras, transparentes y sostenibles. El equilibrio no aparecerá solo. Habrá que negociarlo, diseñarlo y defenderlo.
El descubrimiento en LLM ya es un asunto de negocio
Durante mucho tiempo, la lógica dominante fue relativamente clara: producir contenido relevante, optimizarlo para buscadores, mejorar velocidad de carga, titular bien, cuidar indexación y competir por tráfico. Esa lógica no desaparece, pero se vuelve insuficiente.
Los sistemas basados en IA no siempre navegan como un usuario humano. Muchas veces consumen datos estructurados, interpretan entidades y relaciones, consultan endpoints, procesan sitemaps, leen marcado semántico y dependen de señales de claridad para reducir errores de interpretación. En otras palabras, para las máquinas, una superficie digital clara y estructurada puede ser más útil que una página visualmente impecable pero ambigua o difícil de procesar.
Para un medio, eso tiene consecuencias directas.
Si su contenido no se entiende bien en entornos de IA, puede pasar una de tres cosas: no aparece, aparece mal o aparece sin el contexto que protege su marca y su valor editorial. Las tres son peligrosas. La primera reduce visibilidad. La segunda erosiona confianza. La tercera puede diluir reconocimiento y capacidad de monetización.
Por eso este ya no es solo un problema de tráfico. Es un problema de distribución futura, posicionamiento de marca, autoridad editorial y competitividad.
La diferencia entre ser visible en buscadores y ser descubrible por LLM
El buscador tradicional, simplificando mucho, organiza páginas. El sistema basado en LLM intenta comprender significados.
En el mundo clásico del SEO, la página era la unidad principal de competencia. En el entorno LLM, esa lógica se desplaza hacia algo más profundo: entidades, atributos, relaciones y contexto. Dicho de otro modo, no basta con tener un buen artículo sobre elecciones, inflación o fichajes deportivos. El sistema necesita entender con claridad quién escribió, qué organización publica, sobre qué hecho trata, cuándo fue publicado, cuándo fue actualizado, qué tema cubre, con qué otras piezas se relaciona y por qué debería considerarlo confiable.
Aquí está la gran diferencia: el SEO clásico optimizaba para ranking; el descubrimiento en LLM obliga a optimizar para comprensión.
Un ejemplo simple. Un portal económico publica una nota sobre la decisión de un banco central. Si la pieza tiene un titular claro, fecha visible, autor identificado, tema correctamente categorizado, datos estructurados tipo NewsArticle, enlaces a contexto previo, una URL estable y un sitemap bien mantenido, le da a la máquina una historia inteligible. Si, en cambio, la nota está enterrada en una arquitectura caótica, con etiquetas inconsistentes, fecha ambigua, autor genérico y fuerte dependencia de JavaScript para renderizar el contenido, el sistema tendrá más dificultad para leerla correctamente.
La nueva regla: el buen contenido debe venir bien empaquetado
En medios, solemos pensar en el contenido como una pieza editorial. Para los sistemas de IA, además de pieza editorial, debe ser también un objeto bien descrito.
Eso exige ordenar el contenido en varias capas.
La primera capa es la claridad editorial. Titulares precisos. Bajadas útiles. Cuerpos de texto bien estructurados. Subtítulos que orienten. Párrafos que definan con nitidez quién, qué, cuándo, dónde y por qué. Esto no es una concesión a las máquinas. Es buen periodismo. Pero ahora también funciona como una señal de legibilidad algorítmica.
La segunda capa es la estructura semántica. El contenido debe tener una jerarquía visible y lógica. Una cobertura sobre un escándalo político, por ejemplo, no debería ser una isla. Debe relacionarse con perfiles de protagonistas, cronologías, piezas explicativas, documentos fuente, coberturas previas y actualizaciones posteriores. En lenguaje sencillo: el sitio debe ayudar a la máquina a entender que no son páginas sueltas, sino partes de un mapa de conocimiento.
La tercera capa es la consistencia. Si un mismo tema se etiqueta hoy como “Elecciones 2026”, mañana como “Comicios” y pasado mañana como “Política electoral”, el medio complica la tarea de interpretación. La taxonomía deja de ser un asunto administrativo y se convierte en una señal estratégica. Un sitio consistente enseña. Un sitio desordenado confunde.
Feeds, APIs, sitemaps y metadatos: la tubería que ahora importa más
Hay una frase que muchos medios tendrán que asumir cuanto antes: las máquinas no “viven” la experiencia del sitio; consumen sus datos.
Traducido al mundo editorial, esto significa varias cosas.
Un feed bien diseñado no es solo un archivo para distribución. Puede convertirse en una vía útil para que terceros entiendan qué publica el medio, con qué frecuencia, sobre qué temas y con qué atributos. En noticias, un sitemap específico para contenido noticioso permite informar mejor sobre artículos recientes y sus datos relevantes.
Una API limpia y ordenada permite exponer contenido, metadatos, actualizaciones, catálogos temáticos, perfiles de autores o bases documentales de forma consistente. No todos los medios necesitan abrir APIs públicas desde mañana. Pero sí necesitan pensar como si su contenido debiera poder circular de forma estructurada y comprensible.
Los metadatos son el idioma auxiliar de la página. No sustituyen al periodismo, pero ayudan a describirlo. Fecha de publicación, fecha de modificación, autor, sección, tipo de pieza, idioma, organización editora, imagen principal, temas asociados, formato y relación con otras piezas son señales que reducen ambigüedad.
Y las URLs estables también cuentan. Una página cuyo enlace cambia innecesariamente o depende de parámetros opacos pierde claridad y trazabilidad. Para una máquina, una URL limpia y persistente ayuda a consolidar identidad y contexto.
Los datos estructurados no son decoración: son contexto legible
Muchos medios todavía tratan el marcado estructurado como una tarea secundaria. Error.
Los datos estructurados, usando vocabularios como Schema.org, ayudan a los sistemas a entender qué es una página y qué representa cada elemento. En noticias, NewsArticle permite describir piezas periodísticas; Organization y NewsMediaOrganization ayudan a identificar al publisher; y propiedades vinculadas a autoría, fecha, imágenes o principios editoriales aportan contexto adicional.
Para un directivo no técnico, la mejor analogía es esta: el contenido es la noticia; el dato estructurado es la ficha técnica que permite que una máquina no adivine, sino entienda.
Y en esta etapa, reducir la necesidad de que la máquina “infiera” es una ventaja competitiva.
Autoría, fecha, jerarquía temática y confianza: señales que ya pesan más
En periodismo, confianza y atribución siempre importaron. En la era LLM, importan doble.
Por eso un medio que quiera ser más reusable por sistemas de IA debería cuidar, como mínimo:
- la identidad del autor y su ficha;
- la organización publicadora y sus principios editoriales;
- la fecha original y la fecha de actualización;
- la pertenencia temática de cada pieza;
- la relación entre breaking news, análisis, contexto y archivo;
- la consistencia entre lo visible para el usuario y lo declarado en los metadatos.
Cuando todo eso está alineado, el medio se vuelve una fuente más clara, trazable y reusable.
Errores que están reduciendo la visibilidad de muchos medios
Aquí aparece una parte incómoda: muchos sitios periodísticos siguen operando con arquitecturas que fueron aceptables para otra etapa del internet.
Los errores más frecuentes son bastante reconocibles.
El primero es confiar demasiado en la capa visual. Sitios muy atractivos para humanos, pero difíciles de procesar para máquinas por exceso de scripts, componentes anidados o renderizado deficiente.
El segundo es bloquear o limitar sin querer la accesibilidad de crawlers reputados.
El tercero es usar taxonomías pobres o inconsistentes. Etiquetas improvisadas, secciones duplicadas, temas mezclados, categorías sobredimensionadas.
El cuarto es carecer de disciplina en fechas y actualizaciones. Cambiar fechas sin claridad, no distinguir publicación original de actualización o mostrar señales contradictorias daña comprensión y credibilidad.
El quinto es pensar que una “página especial para IA” resuelve el problema. No se trata de inventar un escaparate artificial para LLM, sino de mejorar la calidad estructural real del ecosistema digital.
Qué hacer ahora
Un medio no necesita rehacer todo su sitio esta semana. Pero sí necesita empezar con una hoja de ruta seria.
Primero, haga una auditoría de superficie legible por máquinas. Revise qué ve realmente un crawler en sus páginas clave, si el contenido principal renderiza bien, si los artículos tienen datos estructurados correctos, si sus sitemaps están actualizados y si la accesibilidad no está siendo limitada sin intención.
Segundo, ordene la taxonomía editorial. Menos etiquetas improvisadas y más arquitectura temática coherente. Un tema debe ser un tema en todo el sitio.
Tercero, fortalezca las señales de confianza. Autoría clara, fichas de autores, principios editoriales, datos de contacto, políticas visibles, fechas coherentes y correcciones transparentes.
Cuarto, trabaje el sitio como un sistema de conocimiento, no como una colección de páginas sueltas. Conecte perfiles, coberturas, dossiers, explicadores, cronologías y archivos.
Quinto, alinee a redacción, producto, SEO y tecnología. Porque este desafío no pertenece a un solo departamento. Es una nueva disciplina transversal.
El punto de fondo: aquí no se juega solo una mejora técnica
La discusión sobre descubrimiento en LLM puede parecer una conversación de especialistas. No lo es.
Lo que está en juego es quién será legible en la nueva capa de intermediación digital. Quién podrá seguir siendo fuente. Quién conservará atribución. Quién convertirá su archivo en activo reutilizable. Y quién correrá el riesgo de producir valor que otros sistemas resumirán sin devolverle suficiente reconocimiento.
Para los medios, esta conversación llega en un momento delicado: ingresos presionados, audiencias fragmentadas, dependencia de plataformas y necesidad urgente de construir ventajas que no se evaporen con el siguiente cambio del algoritmo. Precisamente por eso, ordenar la arquitectura editorial para sistemas de IA no es una tarea cosmética. Es una inversión en capacidad de descubrimiento, autoridad y futuro.
La buena noticia es que esta transición no exige abandonar el periodismo. Exige hacerlo más inteligible.
Porque en la era de la IA, seguirán ganando los medios que informen mejor. Pero también, cada vez más, los que estén mejor estructurados para que las máquinas puedan reconocer que informan mejor.
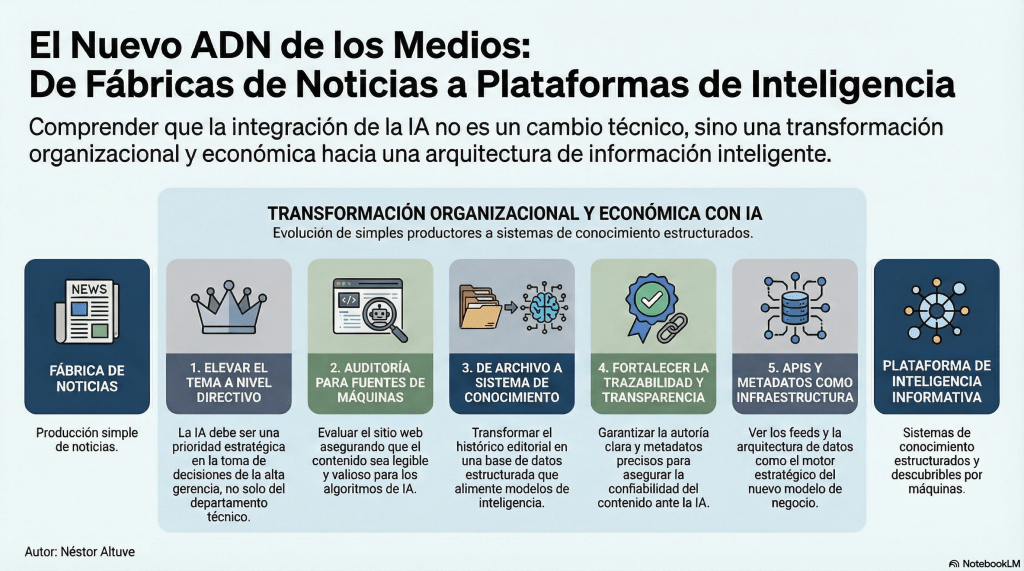
Cinco recomendaciones ejecutivas para dueños y altos directivos de medios
- Eleve este tema a nivel de dirección. No lo deje solo en SEO o tecnología. Afecta distribución, marca, monetización y competitividad.
- Audite su sitio como si fuera una fuente para máquinas. Revise renderizado, datos estructurados, sitemaps, accesibilidad de crawlers, metadatos y consistencia editorial.
- Convierta su archivo editorial en un sistema de conocimiento. Más conexiones temáticas, más contexto, mejores entidades, menos páginas aisladas.
- Fortalezca autoría, fechas, transparencia y trazabilidad. En noticias, esas señales son parte de la confianza y de la correcta interpretación algorítmica.
- Piense en feeds, APIs y metadatos como infraestructura estratégica. No son tuberías invisibles. Son el puente entre su periodismo y los sistemas de IA que ya median, en parte creciente, el acceso a la información.
